Why your data agent keeps writing SQL that double-counts
At a glance
Fan and chasm traps, and how ktx compiles intent into safe SQL over a reviewed join graph.
Fan and chasm traps, and how ktx compiles intent into safe SQL over a reviewed join graph.
Part 1 of 6. BUILDING A CONTEXT LAYER FOR DATA AGENTS.
This is the first in a series about the context an agent needs to query a data warehouse and get the right answer. Point an LLM agent at raw tables and it can write SQL. It can't tell which join fans out, which table is canonical for revenue, or which of three tools' definitions of "active customer" you mean. A context layer is the reviewed knowledge that closes that gap: the metrics, joins, and meaning an agent needs, kept in files you can read and version.
I'll work through it one problem at a time: compiling a question into safe SQL, recovering the joins a warehouse never declared, reconciling metrics that different tools define differently, and keeping the whole thing trustworthy once machines are writing it. On each, I'll show how ktx, the open-source context layer I work on, handles it in real code.
It starts with the failure that makes the rest necessary: an agent that writes SQL the database happily runs, and that still returns the wrong number.
A number that is wrong, and a query that is fine
A query can be valid SQL and still return the wrong number. Here is the one most analysts, and most LLM agents, write a hundred times a week: how much revenue came from orders that included a clearance item?
The amount lives on orders (one row per order). The clearance flag lives on
order_items (one row per line). To filter on the flag you have no choice but to
join the two and sum the order amount. The agent ships a clean-looking result: the
SQL parses, it runs, it returns a number. The number is too big. Here is why:
ordersholds one row per order, andorder_itemsholds one row per line.- The join repeats each order once per matching line, so five clearance lines become five rows.
sum(orders.amount)adds that order's total once per row: a $100 order counts as $500.
Nothing in the query is syntactically wrong. It is valid SQL and invalid analytics: every clause runs, and the total is still inflated because the values were double-counted.
This is the fan trap: a one-to-many join multiplies the rows on the "one" side, and any aggregate over those rows silently over-counts.
Its meaner sibling is the chasm trap: two independent fact tables both join to a shared dimension (orders and support tickets, say, both hanging off customers), and joining all three first makes each fact's rows multiply the other's. Sum revenue and ticket counts in the same query and both come back inflated by the other's cardinality. Snowflake's own engineering team describes the mechanism plainly:
Double counting occurs when a measure ... is summed multiple times because it appears in repeated rows at a lower-level entity (such as order line items). This inflates totals and yields incorrect results.

What makes this dangerous is not that it is hard. Any data engineer can name the fan trap. What makes it dangerous is the failure mode. The query does not error. It does not warn. It returns a confident, plausible, wrong number that flows into a dashboard, a board deck, or an agent's next reasoning step.
And the move toward LLM agents writing SQL on demand multiplies the exposure. An agent generating text-to-SQL has read your column names and maybe a few sample rows, but it has no durable model of which joins fan out and which do not. It guesses the join path every time, and a plausible guess is exactly the thing that double-counts.
So the question is practical: how do you let an agent answer "revenue by segment" without being one bad join away from a wrong number?
Not with a smarter prompt. With a change in who owns the join.
Stop letting the asker write the join
The idea is older than LLMs, and every serious analytics tool is built on it: separate what you want from how it is computed.
When an agent writes raw SQL, it holds both at once. It has to know the measure it wants (sum of order amount), and simultaneously the entire plumbing: which tables to join, which key links them, what grain to aggregate at, how to keep one fact from inflating another, and what dialect the warehouse speaks. Intent and mechanism are tangled in a single string, and the mechanism is the part that goes wrong. The fan trap lives entirely in the how.
A semantic, or declarative, querying layer cuts that string in two. The asker
(agent or human) states only the what: the measures, the dimensions to slice
by, the filters. A compiler owns the how: it picks the join path, decides the
grain, chooses a fanout-safe SQL shape, and emits dialect-correct SQL. The asker
never writes a JOIN. There is no join for it to get wrong.
It is a well-populated design space. The neighbors worth knowing:
- Plain text-to-SQL keeps the asker in charge of the how and tries to make the model good enough to get it right. It is the most flexible and the most exposed, because every query is a fresh chance to fan out.
- dbt's Semantic Layer / MetricFlow, Cube, and Malloy are the mature declarative players. You define metrics, entities, and join relationships once, and the engine compiles queries against them. They differ in surface and ergonomics but share the core bet: relationships are declared up front, not rediscovered per query.
- BI tools like Looker's LookML and Metabase's models make the same move from a different angle, asking you to declare explores and relationships so report authors pick fields instead of writing joins.
dbt's own benchmark puts numbers on the difference. It frames the two failure modes like this:
With text-to-SQL, failure looks like a plausible but incorrect answer. With the Semantic Layer, failure looks like an error message.
In their tests, moving a model from raw text-to-SQL onto a semantic layer raised accuracy across the board. The jump was sharpest on the many-hop join questions where fan and chasm traps live:
| Workload | Text-to-SQL | Semantic layer |
|---|---|---|
claude-sonnet-4-6, overall | 90.0% | 98.2% |
gpt-5.3-codex, overall | 84.1% | 100% |
| Many-hop join questions | 51.2% | 100% |
Those are dbt's numbers, but the pattern generalizes to any tool that owns the join. ktx is one of them, and the lesson holds even if you never run it: the durable fix for double-counting is not a better query writer. It is a reviewed, declared model of your data's grain and relationships, plus a compiler that refuses to emit an aggregation it can't prove is safe. The asker declares intent. The model owns the join.

ktx differs from its neighbors not in the declarative bet (it shares that), but in two things: it treats the model as a reviewed, version-controlled artifact that a context engine builds and keeps current from your real stack, and it is deliberately fail-closed about cases it can't prove safe. The rest of this post is that compiler.
How ktx compiles intent into safe SQL
ktx is an open-source context layer for data agents. One pillar of that layer is a semantic layer: a compiler that turns a short declarative query into dialect-correct SQL over a reviewed join graph. It is the piece that makes the fan trap structurally impossible to hand to an agent, because the agent never writes the join. Four mechanics carry the work: the query contract, the planner, the join graph, and the fanout defense.
The query contract: intent, fully qualified
An agent talks to the semantic layer with a small JSON payload, a semantic
query. Every field is optional except measures:
measures: named pre-defined measures likeorders.revenue, or inline expressions likesum(orders.amount).dimensions: columns to group by, each optionally carrying agranularityfor time fields.filters: row-level predicates, which the planner later sorts intoWHEREorHAVINGfor you.segments: named, reusable filter sets defined on a source and applied as extra predicates.order_by: sort fields with an optional direction.limit: a row cap, defaulting to 1000.
A real call is unremarkable:
{
"measures": ["orders.revenue", "tickets.ticket_count"],
"dimensions": ["customers.segment"],
"filters": ["orders.created_at >= '2025-01-01'"],
"limit": 1000
}Notice what is not in there: no FROM, no JOIN, no GROUP BY, no WITH. The
agent names no table relationship, and it can't be vague about where a column
lives. Column references are fully qualified as source.column, so the
compiler never guesses which table a bare amount or segment came from. (Bare
names are accepted only when they resolve to exactly one source. An ambiguous one
is an error, not a coin flip.) That payload is the entire contract. The dangerous
parts of the original query, including the join between orders and tickets
where a chasm trap hides, are now the planner's job, not the agent's.

The planner: a deterministic pipeline, not a guess
That payload runs through a fixed pipeline before any SQL is emitted. The same steps run in the same order every time, which makes the result defensible rather than improvised:
- Resolve references. Qualify bare columns, look up pre-defined measure
expressions (so
orders.revenueexpands to its realsum(case when status != 'refunded' then amount end)body and any attached filter), and classify each measure as raw or derived. - Pick an anchor and build the join tree. Pick an anchor source (a dimension or a measure source) to root the join tree, then run a shortest-path search across the typed join graph to reach every other source the query references. The path comes from the graph, not from the order the agent listed things.
- Detect fanout. Group the measures by the source that owns them. If more than one independent group survives, the planner has found a chasm trap and switches compilation strategy. This is the load-bearing step, and the next section is entirely about it.
- Classify filters. Split each predicate into row-level (
WHERE) or aggregate-level (HAVING) based on whether it references a measure, so the agent's flatfilterslist lands in the right clause without the agent knowing the distinction exists. - Generate SQL. Emit Postgres-shaped SQL: a single-source aggregation when the query is provably safe, per-source pre-aggregated CTEs when fanout is present.
- Transpile. Run the result through
sqlglotso the warehouse receives syntax it actually speaks (BigQuery, Snowflake, DuckDB, MySQL) without any dialect-specific generation logic upstream.
ktx writes one SQL shape (Postgres) and transpiles at the very end, rather than carrying a separate code path per warehouse. One way to compile, many dialects out. Fewer code paths means fewer places for the join logic to diverge and mis-handle one engine.
The join graph: declared facts, not runtime inference
The planner's join decisions are only as trustworthy as the graph it walks, and
that graph is the heart of why ktx doesn't double-count. Each semantic source
is a node. Each declared join is a typed edge carrying a relationship:
many_to_one, one_to_many, or one_to_one. The graph is bidirectional. Every
forward edge gets a reverse with the relationship inverted (many_to_one becomes
one_to_many going the other way), so the planner can anchor on any source and
still traverse correctly. That edge type is not decoration. It is exactly the
signal that distinguishes a safe join from a fan trap.
The edges and grain come from reviewed YAML, and the compiler treats them as fact, not as something to re-derive at query time:
# semantic-layer/warehouse/orders.yaml
name: orders
table: public.orders
grain: [order_id]
joins:
- to: customers
on: customer_id = customers.id
relationship: many_to_one
- to: order_items
on: id = order_items.order_id
relationship: one_to_many
measures:
- name: revenue
expr: sum(case when status != 'refunded' then amount end)Read that one_to_many edge to order_items and you are looking at the fan trap
declared, in writing, as a known hazard. Because the relationship is recorded, the
planner knows, before it generates a line of SQL, that summing an orders
measure across an order_items join would multiply rows. The hazard the agent
couldn't see is a typed property of the graph.

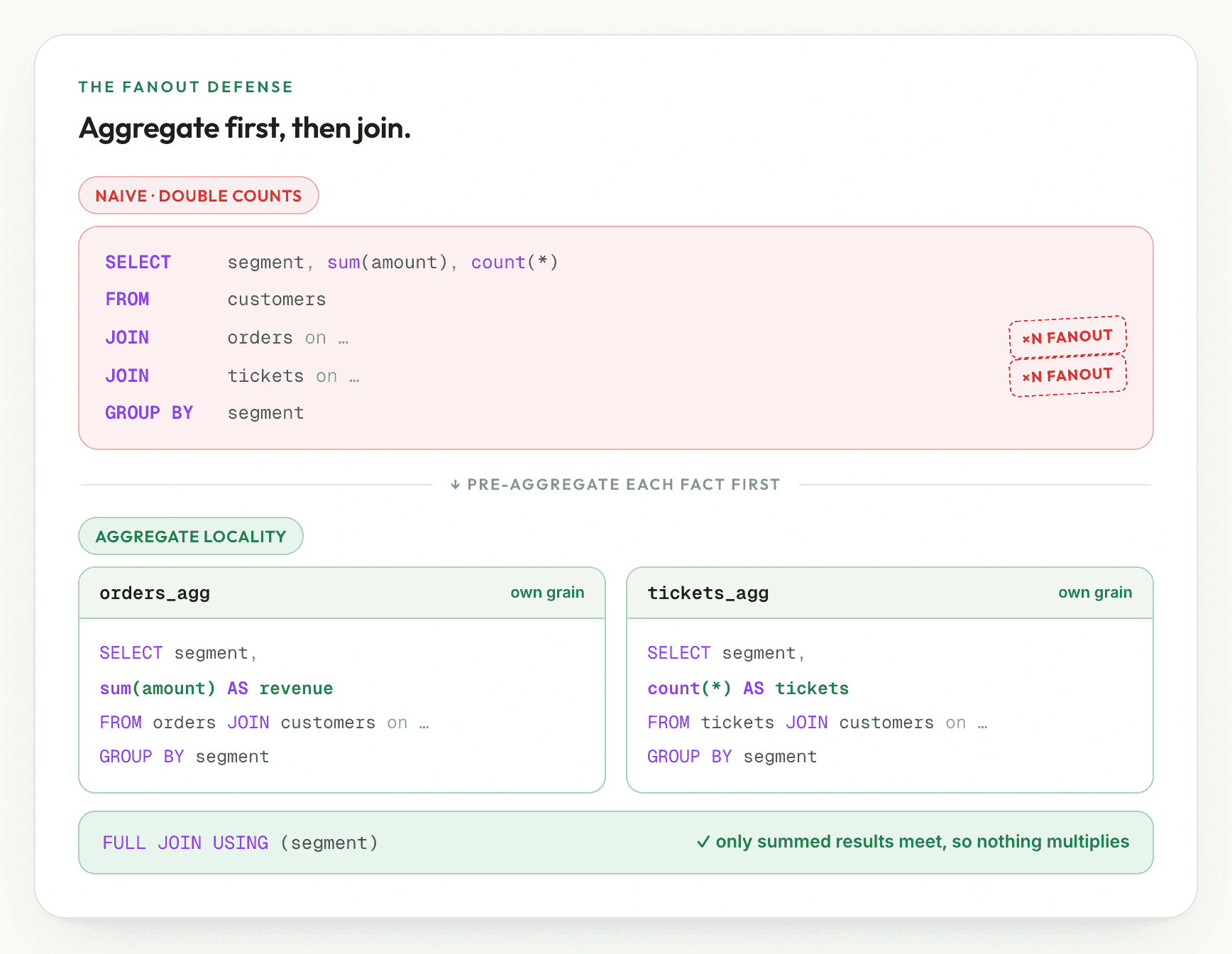
The fanout defense: aggregate locality
This is where intent becomes a correct number. When the planner groups measures by their owning source and finds more than one independent group (orders' revenue and tickets' count, the chasm-trap shape), it does not join the facts together and hope. It marks the query as a chasm trap and switches to aggregate locality.
Aggregate locality is the join shape an analyst writes by hand once they have been
burned by the fan trap. Instead of joining everything and then aggregating, each
fact is pre-aggregated at its own grain inside its own CTE, and only the
already-summed results are joined back to the shared dimension at the end. Revenue
is summed across order rows alone, before any ticket row can multiply it. Ticket
count is summed across ticket rows alone, before any order can. The
multiplication never happens because the facts never meet at row level. The single
fan-trap case (one measure source reaching a dimension through a one_to_many
edge) gets the same treatment: pre-aggregate the measure before the multiplying
join.
A further field, include_empty (default true), controls whether that final join
keeps every fact's rows (a FULL JOIN) or drops the unmatched ones with an inner
join.
The contrast:
| Naive SQL shape | ktx's shape |
|---|---|
| Join facts and dimensions first, then aggregate | Aggregate each fact at its own grain, then join |
One outer WHERE for every filter | Keep each measure's filter with its measure source |
| Trust the shortest textual join path | Walk typed safe paths and reject disconnected sources |
| Let dimension grain differ across facts | Raise when an asymmetric dimension would fan out a measure |
The ktx posture that ties this series together: when the planner can't prove
a shape is safe, it raises instead of guessing. A filter that would force a
one_to_many join from a measure's source (and so reintroduce the very fanout the
CTEs exist to prevent) is rejected with an error that says why, not silently dropped
or multiplied. The semantic layer follows the same rule as the rest of ktx: a
result it can't stand behind is an error, never a wrong number. That is the dbt
benchmark's distinction made concrete. Failure looks like an error, not a plausible
lie.
What this buys you, and where the series goes next
Strip away the ktx-specific names and one lesson remains: do not ask the model to write the join. The fan trap and the chasm trap are not reasoning failures you can prompt your way out of. They are properties of grain and cardinality that have to be declared somewhere a compiler can read them. Move the join into a reviewed model, give an aggregation-aware planner the relationship types, and let it pre-aggregate where the data fans out. The asker states intent. The model owns the mechanism that goes wrong.
What ktx's choices add, beyond the general technique:
- The join graph is a version-controlled artifact you review like code, not a black box.
- The compiler is deterministic and fail-closed, so an unprovable query is an error rather than a confident inflation.
- One Postgres-shaped generation path transpiles to every warehouse, so the safety logic doesn't fork per dialect.
But all of that rests on one assumption this post quietly made: that the join graph is there, correct, and current. A reviewed graph of typed relationships is exactly what most warehouses don't hand you. Foreign keys go undeclared, relationships live in someone's head, and definitions drift across tools.
The rest of this series is about earning that graph and keeping it honest:
- Part 2 is how ktx infers those typed edges statistically and validates them against real data.
- Part 3 reconciles the contradictory definitions of "revenue" that dbt, Looker, and Metabase each carry.
- Part 4 covers how the graph is built and maintained by LLM agents without ever landing a silently wrong edit.
- Part 5 is how all of it gets served to agents over MCP.
- Part 6 is how a machine-maintained semantic layer stays auditable, reviewed like code.
The compiler in this post is only safe because everything those posts describe keeps its inputs true.
Part 1 of 6. BUILDING A CONTEXT LAYER FOR DATA AGENTS.
FAQ
What is a fan trap in SQL?
A fan trap is a one-to-many join that multiplies the rows on the "one" side. Join
orders to its line items and each order repeats once per line, so
sum(amount) adds that order's total several times over. The query parses and
runs, and the number it returns is silently inflated.
What is the difference between a fan trap and a chasm trap?
A fan trap multiplies one fact's rows through a single one-to-many join. A chasm trap is the meaner version: two independent fact tables (say orders and support tickets) both join to a shared dimension, and joining all three makes each fact's rows multiply the other's. Both inflate totals with no error.
Why do LLM agents and text-to-SQL tools double-count?
An agent generating text-to-SQL has read your column names and maybe a few sample rows, but it holds no durable model of which joins fan out. It guesses a join path on every query, and a plausible guess is exactly the thing that double-counts: valid SQL, invalid analytics.
How does a semantic layer prevent SQL double-counting?
It separates what you want from how it is computed. The asker states the measures and dimensions. A compiler owns the join path, the grain, and the SQL shape. When two facts would multiply each other, it pre-aggregates each at its own grain before joining, so the rows never meet to inflate.