When dbt, Looker, and Metabase disagree on "revenue"
At a glance
Reconciling contradictory metric definitions across dbt, Looker, and Metabase, and how ktx flags them instead of silently selecting one.
Reconciling contradictory metric definitions across dbt, Looker, and Metabase, and how ktx flags them instead of silently selecting one.
Part 3 of 6. Building a context layer for data agents.
Conflicting definitions of a single metric
Within one organization, three tools can return three different definitions of revenue. Each was built for a different question:
- In dbt,
fct_orders.revenuesumsamountover every order row, refunds included, for an operations dashboard that measures gross flow. - In Looker, the
total_revenuemeasure excludes refunds and internal test accounts, because finance owns it and reports net. - In Metabase, a saved question called "Revenue (MRR)" divides an annual figure by twelve and counts only subscription line items.
None of these definitions is incorrect. Each is appropriate for the question it was built to answer. The difficulty is that they share a name, and the name propagates beyond its source. A figure is copied into a board deck without the filter that produced it, or an analyst joins the Looker measure to the Metabase question and double-counts.
A text-to-SQL agent compounds the problem.
Given the request "what was revenue last month," an agent that has ingested all
three tools holds three plausible definitions of revenue and must select one.
If it selects one implicitly, as most retrieval-based configurations do, the
result is a confident and specific number with no indication that a selection
occurred. This is worse than the manual case, in which the analyst at least knew
which tool produced the figure.

The remainder of this article examines the design problem this poses for a context layer, and the approach ktx takes to it.
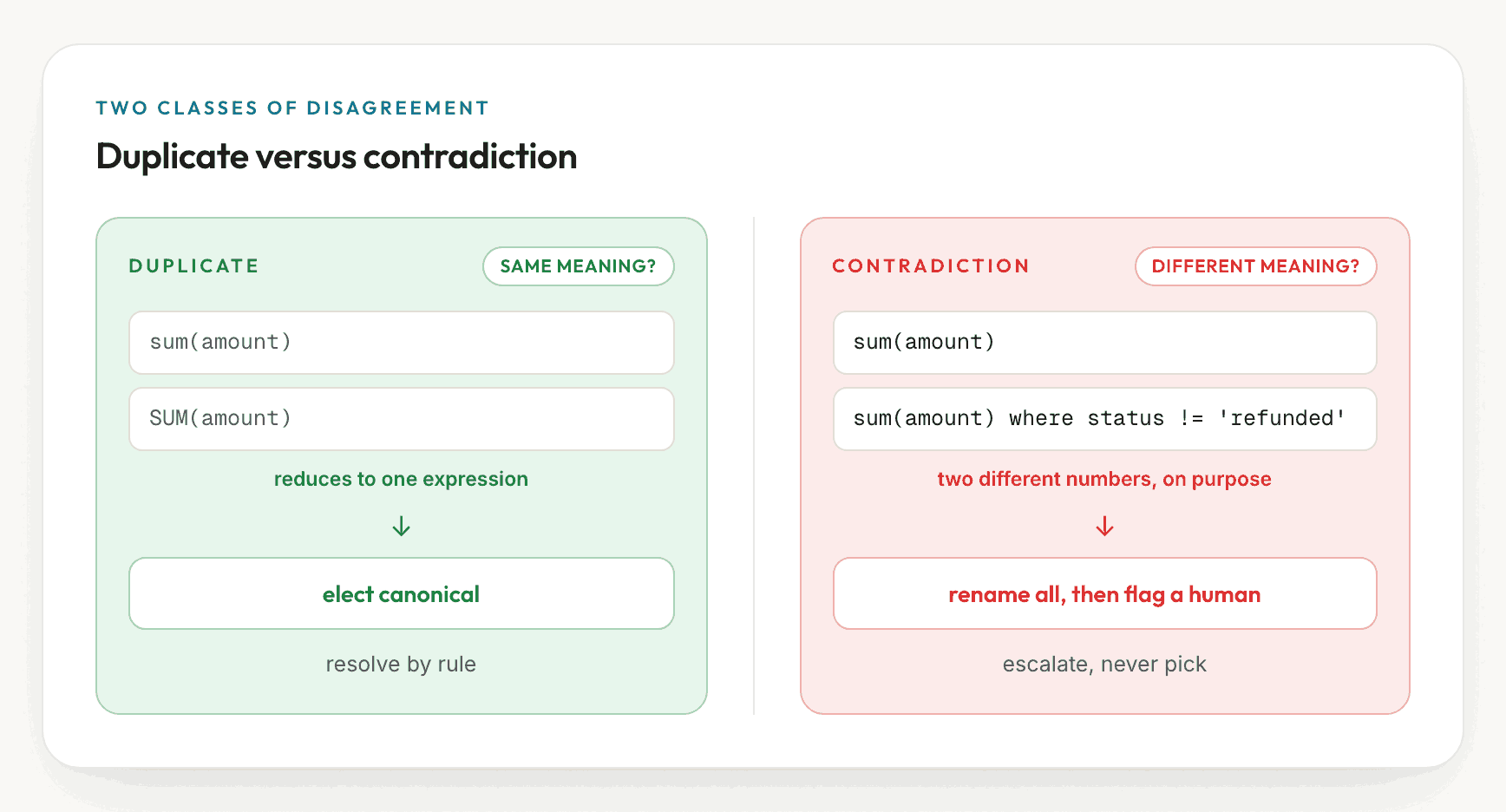
Duplicates and contradictions
The objective is not to identify a single correct definition of revenue, which generally does not exist. It is to determine, for each contested name, whether the variants denote the same quantity or different quantities.
A duplicate is the same metric defined the same way in two locations, apart
from cosmetic differences. dbt's revenue and a Metabase question that computes
sum(amount) over the same table are duplicates. This is a bookkeeping problem.
A contradiction is the same name applied to materially different logic:
different aggregation, filters, or grain. Looker's net total_revenue and dbt's
gross revenue are a contradiction, and they return different numbers on the
same data by design. This is not a bookkeeping problem. A contradiction must not
be resolved by a rule, because no rule is correct. Selecting gross or net is
a business decision
that depends on the requester and the purpose of the query. An ingest pipeline
lacks that context. A person has it.
The two cases require opposite treatment:
- Duplicates are resolved by a total rule, for example by electing the definition that the rest of the stack references most, so that the same inputs always produce the same result.
- Contradictions are captured rather than resolved. Every variant is retained and renamed so the names no longer collide, the contested bare name is withheld from the executable layer, and the case is flagged for human review.
The second is the inverse of silent selection. Alternatives that select implicitly (last-writer-wins, a single hand-curated definition, or designating one tool the single source of truth and ignoring the rest) resolve the question of which definition prevails without recording that a selection was made.
This principle is independent of implementation. Whether the layer is built in dbt, Cube, Malloy, or a context layer such as ktx, the criterion is the same: whether the system selects one definition implicitly, or declines and reports the disagreement.
Conflict handling in ktx
In ktx, ingest converts each connected tool into reviewed semantic-layer files, the same layer that holds the join graph from Part 2. A disagreement surfaces when two writes describe the same metric, under the same connection, with different content. An ordered rule classifies each collision and stops at the first match.
Most collisions are routine. Re-importing a changed source is treated as intended and replaces the prior version, with a flag raised only when the change is structural enough to break a downstream join. The harder cases are two definitions that arrive in the same import run, neither one a re-import of the other.
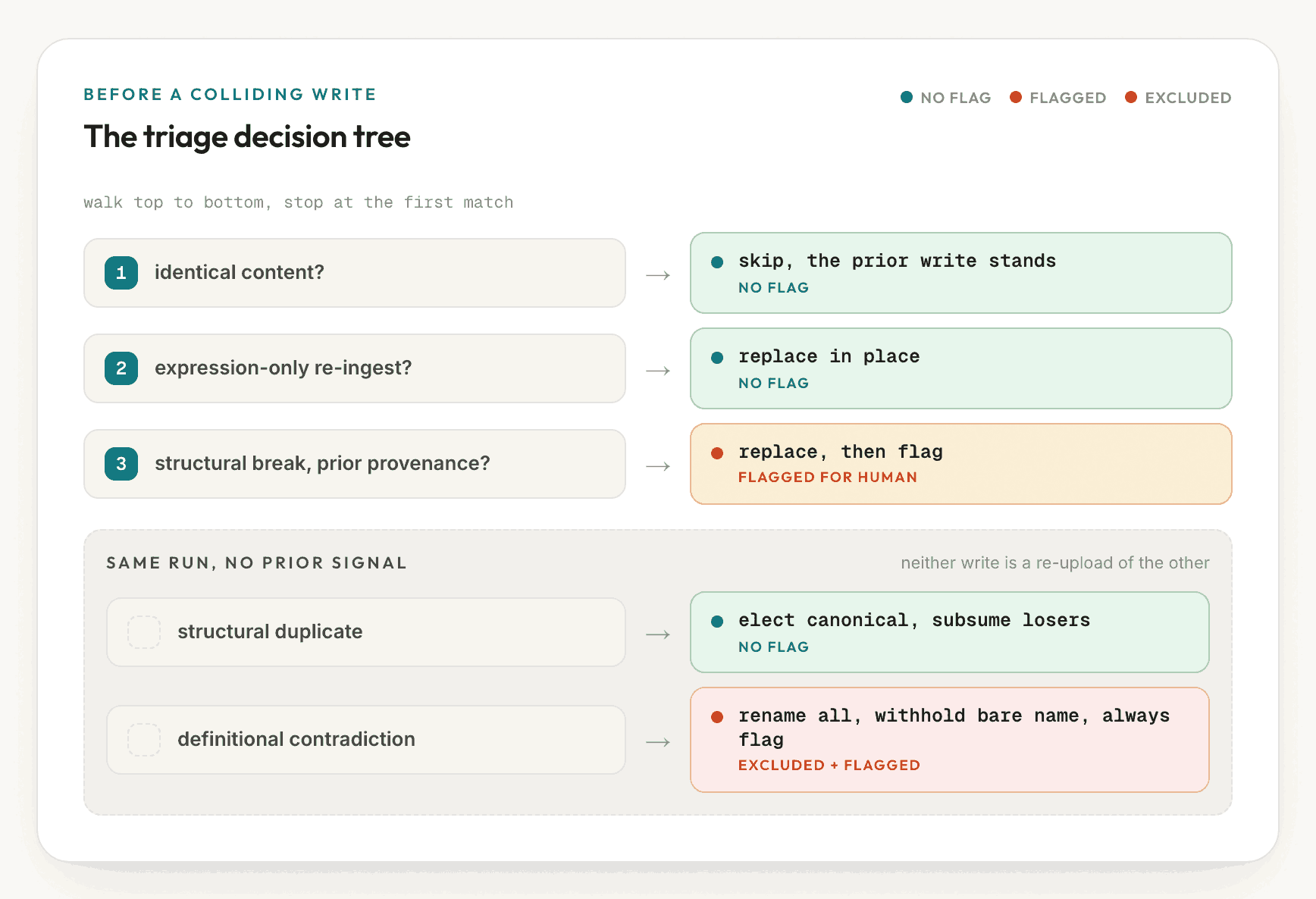
For a same-run duplicate, ktx elects one canonical definition by the total rule and records the alternatives alongside it. No human review is required, because the winner is unambiguous.
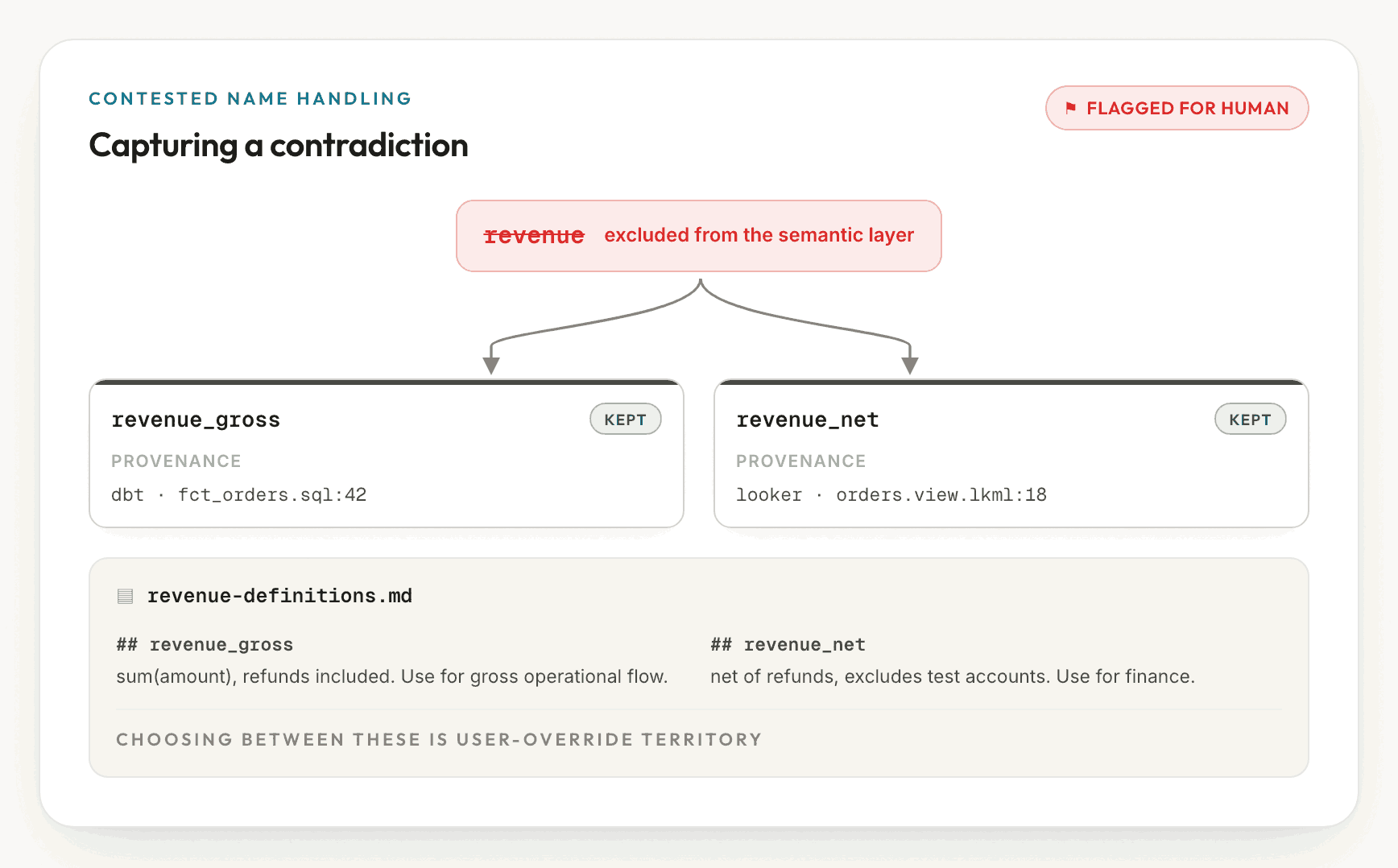
For a same-run contradiction, ktx does not select. It renames each variant
to a descriptive name (revenue_gross and revenue_net, never revenue_1 and
revenue_2), writes a page documenting what each one computes and its origin, and
withholds the bare name revenue from the executable layer. After this, an agent
asked for revenue can no longer retrieve a bare revenue, because it no longer
exists as a runnable measure. The case is flagged for human review, and the
documentation page provides the basis for that decision.
One gap remains. Ingest runs many agents in parallel, and each one sees only its
own portion of the data, so two of them can write conflicting revenue measures
without either being aware of the other. A reconciliation pass runs after all of
them, with a view of the whole run, and applies the same rule across units. Each
decision it makes is written as a record that appears in a report a person
reviews, so a resolved contradiction is recorded rather than discarded.
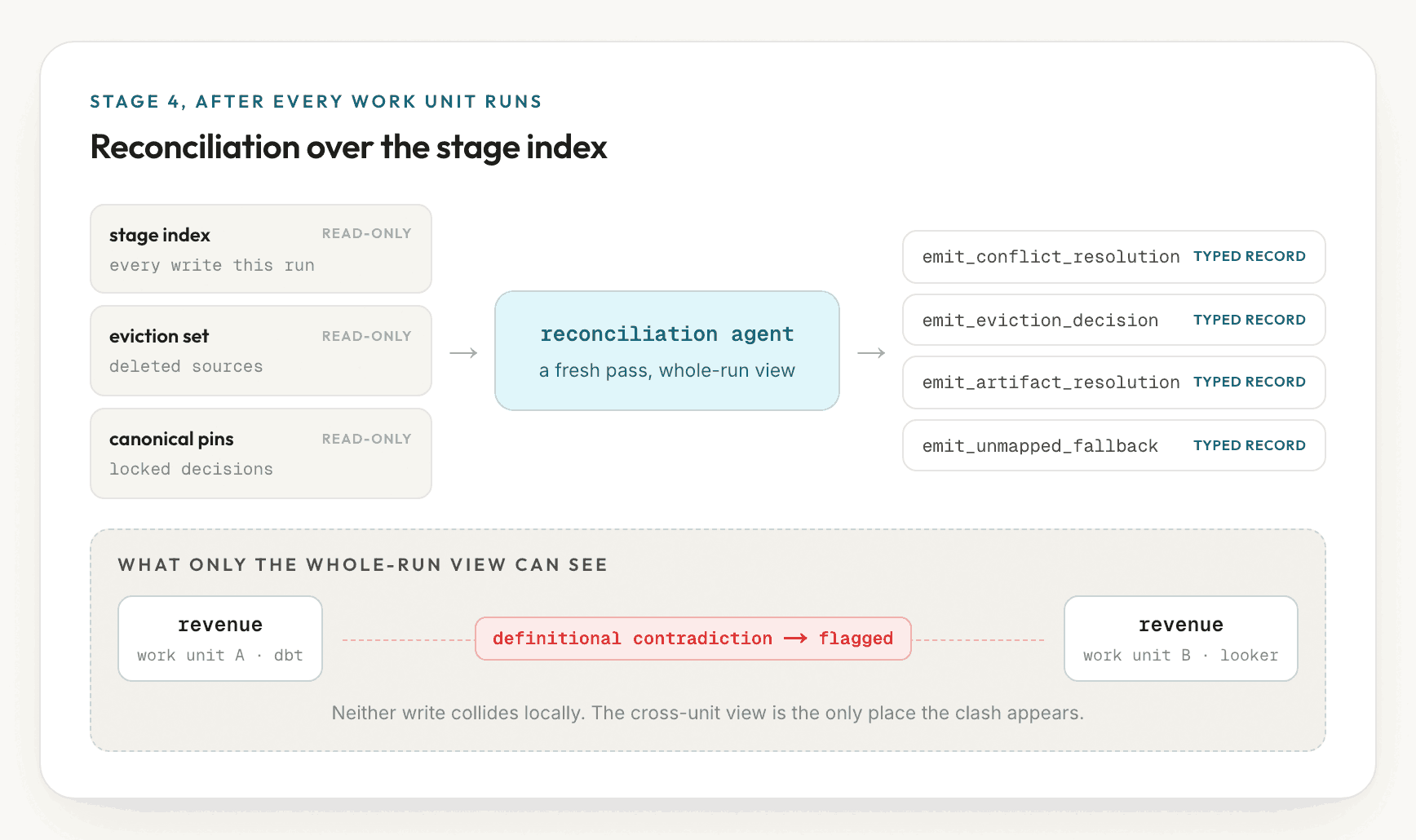
When a person decides, for example that net-of-refunds is the organization's revenue, that decision is stored as a canonical pin. On later runs, ktx retains the pinned definition and stops re-flagging the same contradiction. The tools continue to disagree, but ktx records which definition the organization has designated.
Reliability and validation gates
This logic is a rule written for an LLM agent to apply, not deterministic code, so a model can apply it imperfectly. The design does not depend on the model being correct.
Every write passes through validation before it is committed, and the run is fail-closed: if a conflict cannot be resolved cleanly, the run fails and the existing context is left unchanged. The rule specifies how ktx selects a definition. The validation gates ensure that an incorrect selection becomes a caught error rather than a silent incorrect value in production.
Summary
- Distinguish duplicates from contradictions before anything else. Two expressions of the same meaning are a bookkeeping matter. The same name applied to different meanings is a business decision.
- Resolve duplicates with a total rule, so that the same inputs always elect the same result.
- Do not resolve a contradiction with a rule. Retain every variant, withhold the contested bare name, and flag a person.
- Persist the human decision, so that a one-time choice does not recur as a flag on every run.
- The determinism resides in the validation gates, not in the model that applies the rule.
A further question follows from this design. Once LLM agents maintain this layer over time, their updates have to remain atomic and free of silent errors. The isolation and fail-closed gates that provide that property are the same machinery that makes the conflict logic described here safe to run.