We Built the Open-Source Version of Anthropic's Internal Data Analytics Engine
At a glance
Anthropic published how its data team automated close to 100% of business analytics at 95%+ accuracy. The four-layer architecture they describe is the same one we had already open-sourced as ktx, an independent, Apache-2.0 context engine for data agents.
Anthropic just published their data team's playbook for self-serve analytics: How Anthropic enables self-service data analytics with Claude.
The results are impressive: their agent now automates close to 100% of business analytics requests, and does so at 95%+ accuracy.
The article is a gold mine. It's also a "what-we-did" and not a "how-you-do-it", so rebuilding it at your own company means reverse-engineering most of the hard parts.
We already built it, so you don't have to bother with that: ktx is an open-source context engine that packages the same four layers described by Anthropic's data team, and we shipped it before Anthropic's article went up. We arrived at the same architecture independently, which confirms these are the right four layers. ktx is Apache-2.0, and you can install and run it with one command: github.com/Kaelio/ktx.
This post walks through each component of Anthropic's agentic analytics systems and explains how ktx packages the same four layers as one installable engine that builds and maintains itself, with a human in the loop.
Disclaimer: we are not affiliated with Anthropic and we never saw their code.
Why self-serve analytics fails
Very briefly on this. Even though you might have heard about it hundreds of times, Anthropic articulates the problem behind self-serve analytics in one of the clearest ways we've seen: data is not software. When an agent writes code, the solution space is open-ended and tests catch hallucinations. Analytics is the opposite. "There's often only a single correct answer using a single correct source," and no compiler will tell you when the number is wrong.
They name three reasons agents produce those wrong answers:
- Concept-to-entity ambiguity: "the agent is unable to choose the correct fields that best answer a user's question." The example they cite: "In measuring the number of active users: what actions constitute being 'active'? Do you include fraudulent users? What lookback window do you use?"
- Staleness: "data sources, business definitions, and schemas change constantly; assets and agent knowledge go stale."
- Retrieval failure: "the right information may actually be in the data model and properly annotated, but the agent simply doesn't find it."
Every component below exists to kill one of these three.
Anthropic's agentic analytics stack, layer by layer
Anthropic's stack is four layers, built from the warehouse up. Here is the same stack, annotated with the ktx piece that implements each layer and the failure mode it kills.
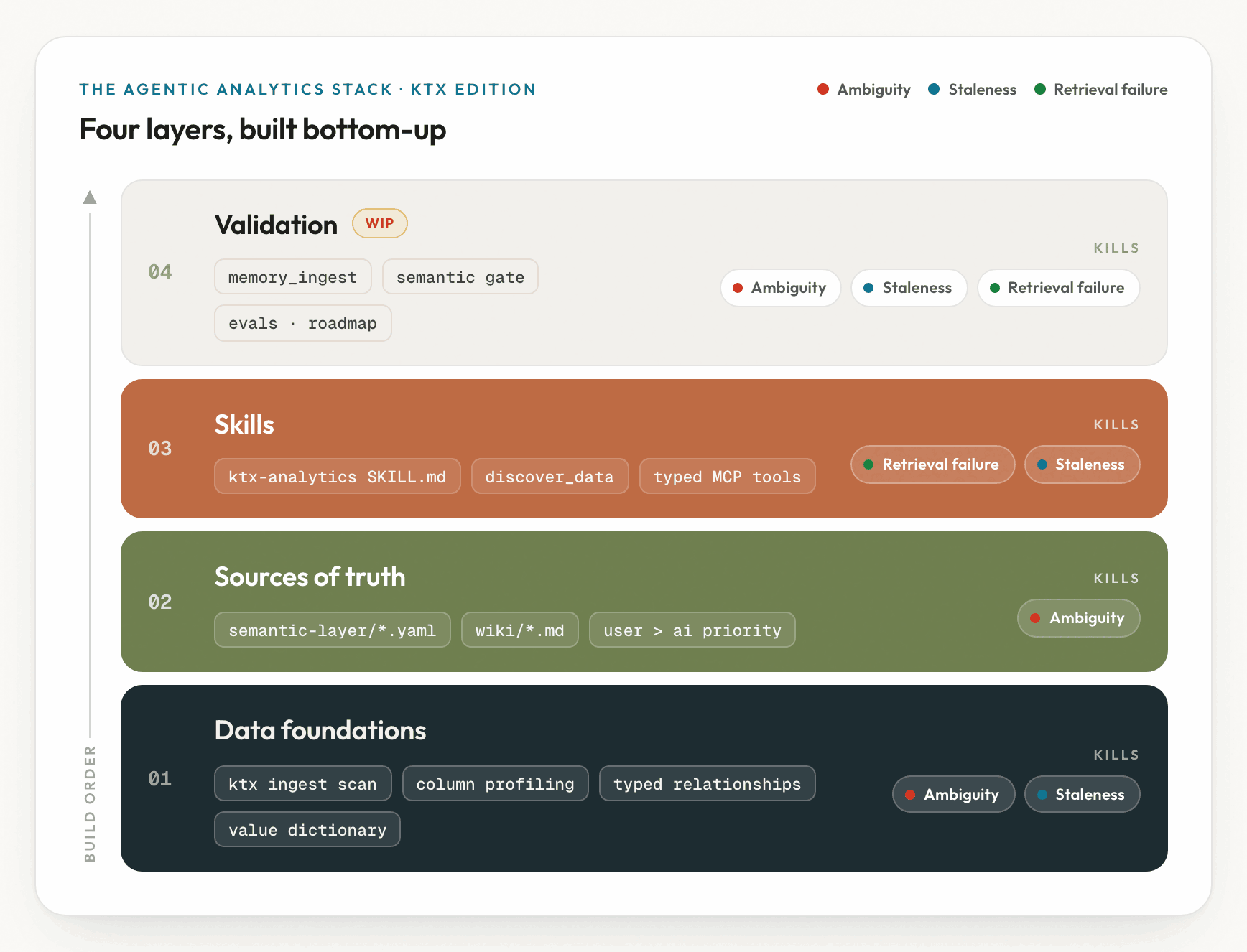
1. Data foundations
Anthropic's definition: "the data models, transforms, tests, and tables in a data warehouse, along with the metadata describing them." They want "column and table descriptions, canonical metric definitions, grain documentation, valid value ranges, lineage, ownership, and model tiering ... maintained with the same rigor as the transformations themselves."
2. Sources of truth
These are the reference surfaces that help the agent navigate: a semantic layer (managed metric definitions), lineage, a query corpus of how real analysts have queried this data, and a business context layer.
A few lessons:
- Business context is critical. They model it as a knowledge graph of indexed docs, roadmaps, decision logs, and their organizational structure.
- Do not let an LLM own the semantic layer. They tried "bootstrapping the semantic layer by having an LLM auto-generate metric definitions from raw tables and query logs," and it "was net-negative on our evals versus a smaller, human-curated layer." Their rule of thumb: "generate the documentation with Claude, but have a human own the definition."
- Do not just dump raw history at the agent. They found that "giving the agent raw retrieval access to thousands of prior queries moved accuracy by less than a point," and that the win comes from distilling that corpus into curated reference docs.
3. Skills
"A folder of markdown the agent reads on demand." Anthropic credits this layer with the entire jump from 21% to 95%+ accuracy. It splits in two: a knowledge skill that "acts as a thin top-level router" loading domain detail on demand, and an unbook skill that "encodes the process a senior analyst would follow: clarify the question, find sources, run the query, and then loop the result through adversarial review sub-agents."
ktx ships this layer in full. It includes a real markdown skill (ktx-analytics) that encodes the same analyst process, and pairs that skill with a typed tool surface the skill drives. More on that in the mapping below.
4. Validation
- Offline evals: Q&A pairs covering the most common business questions, plus long-tail questions about business context, plus human corrections collected on the fly.
- Ablation: systematically removing pieces to see where the bottlenecks are and which changes move accuracy the most.
- Online validation: Anthropic runs a live layer at answer time that challenges the result with adversarial review sub-agents, surfaces provenance, and checks data quality and freshness. They measured adversarial review adding 6% accuracy at the cost of 32% more tokens and 72% higher latency.
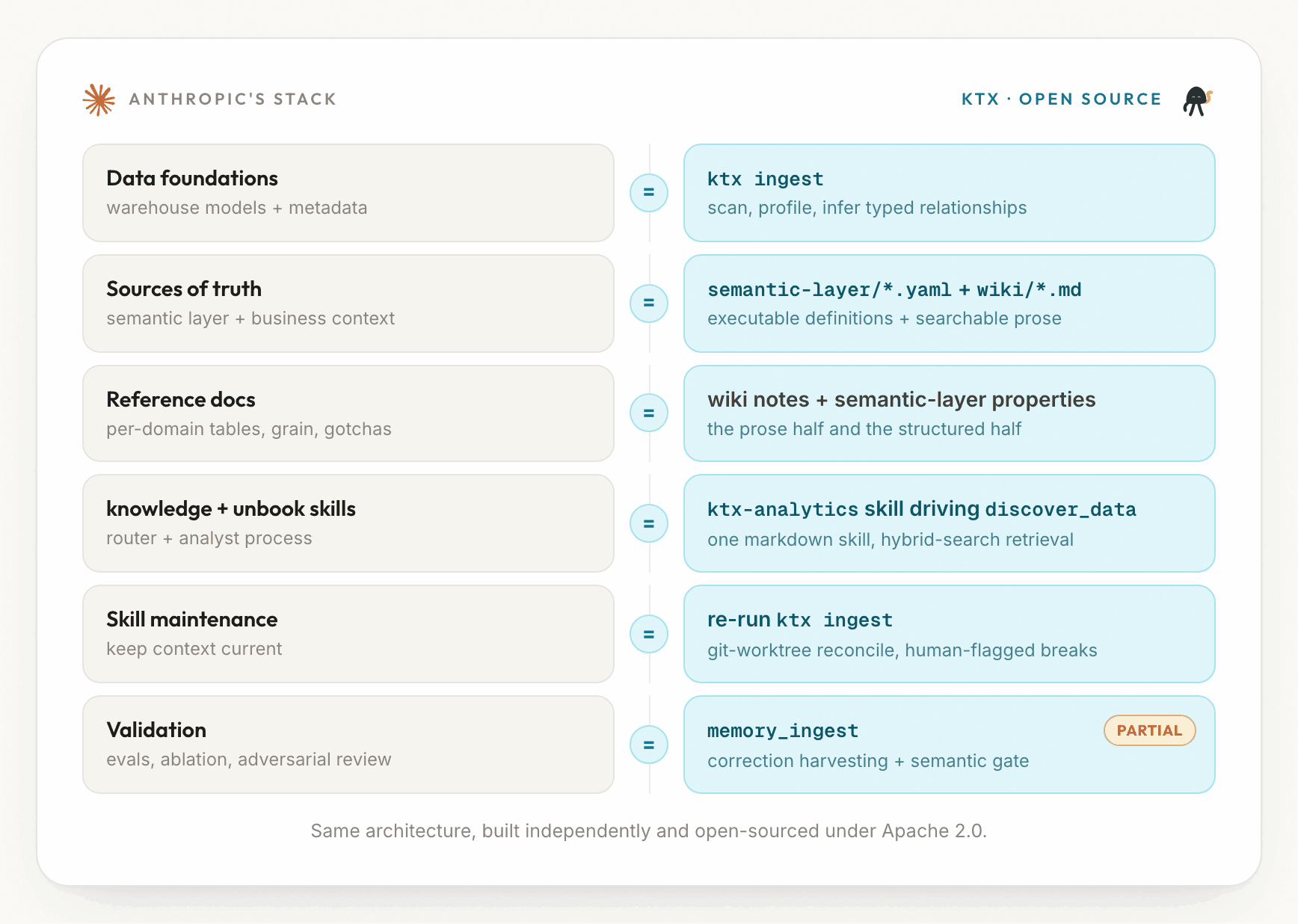
How each ktx concept maps to the Anthropic stack
Here is the whole mapping in one view. Every concept in Anthropic's stack lands on a concrete ktx surface.
| Anthropic's concept | ktx equivalent |
|---|---|
| Data foundations | ktx ingest scans the warehouse, samples tables, infers typed relationships, and pulls from dbt, MetricFlow, LookML, Looker, Metabase, Notion, and query history |
| Sources of truth | A semantic layer (semantic-layer/<conn>/*.yaml) for approved metrics and joins, plus a business-context wiki (wiki/**/*.md) for rules and caveats, both indexed and embedded |
| Reference docs | The wiki carries the prose half (rules, gotchas, ownership), the semantic-layer properties carry the structured half (grain, columns, measures, joins) |
| knowledge skill + unbook skill | One markdown skill, ktx-analytics, encodes the analyst process and routes the agent to typed tools (discover_data, sl_query, wiki_read, and more) |
| Skill maintenance | Re-run ktx ingest. It diffs against the previous sync, reconciles in isolated git worktrees, and flags semantic breaks for a human |
| Validation | memory_ingest harvests corrections and a semantic gate validates definitions, but there is no answer-correctness eval yet |
Two differences are worth calling out, and the first is the opposite of what we expected.
- Skills are not a difference. We ship the same kind of process skill Anthropic does. The genuine difference is in retrieval: Anthropic's knowledge skill has the agent read a folder of markdown on demand, while ktx serves a curated wiki and semantic layer through a ranked hybrid search and a value dictionary. Same job, better-instrumented mechanism.
- Validation is the real gap. This is where Anthropic got their last and hardest gains, and it is where ktx is still building.
The skill that drives the tools
Anthropic's stack has two skills. A thin knowledge skill that routes to the right per-domain reference doc, and an unbook skill that encodes the analyst process. Both of those jobs live in ktx, they are just split differently.
The ktx-analytics skill is installed straight into your coding agent (Claude Code, Claude Desktop, Codex, Cursor, or OpenCode) right next to the MCP connection. It is the unbook skill: it encodes the senior-analyst loop, and it tells the agent which tool to call at each step.
1. Discover call discover_data first, which returns refs only
2. Inspect read the top hits (wiki_read, sl_read_source, entity_details)
3. Resolve dictionary_search to map a value like "enterprise" to a column
4. Plan identify grain, metrics, dimensions, filters, time window
5. Query prefer sl_query, drop to sql_execution only when needed
6. Validate sanity-check totals, filters, nulls, time zones, then state sources
7. Capture memory_ingest durable learnings back into the contextThe knowledge skill's router job is handled at runtime by discover_data, which finds the right context and hands the agent back what to open. So Anthropic's two skills collapse into one ktx skill plus a search tool: the skill is the process, the typed tools are the execution surface, and the skill tells the agent which to call.
Read-only is enforced, not just promised. Every query is checked and rejected unless it is a read, and the one tool that writes touches your context repo, never your warehouse.
Search, not grep
The cleanest difference between a folder of markdown and a context engine is how the agent finds things. Anthropic's knowledge skill has the agent read reference docs on demand. ktx indexes the curated layer at ingest time and serves it through a real retrieval engine.
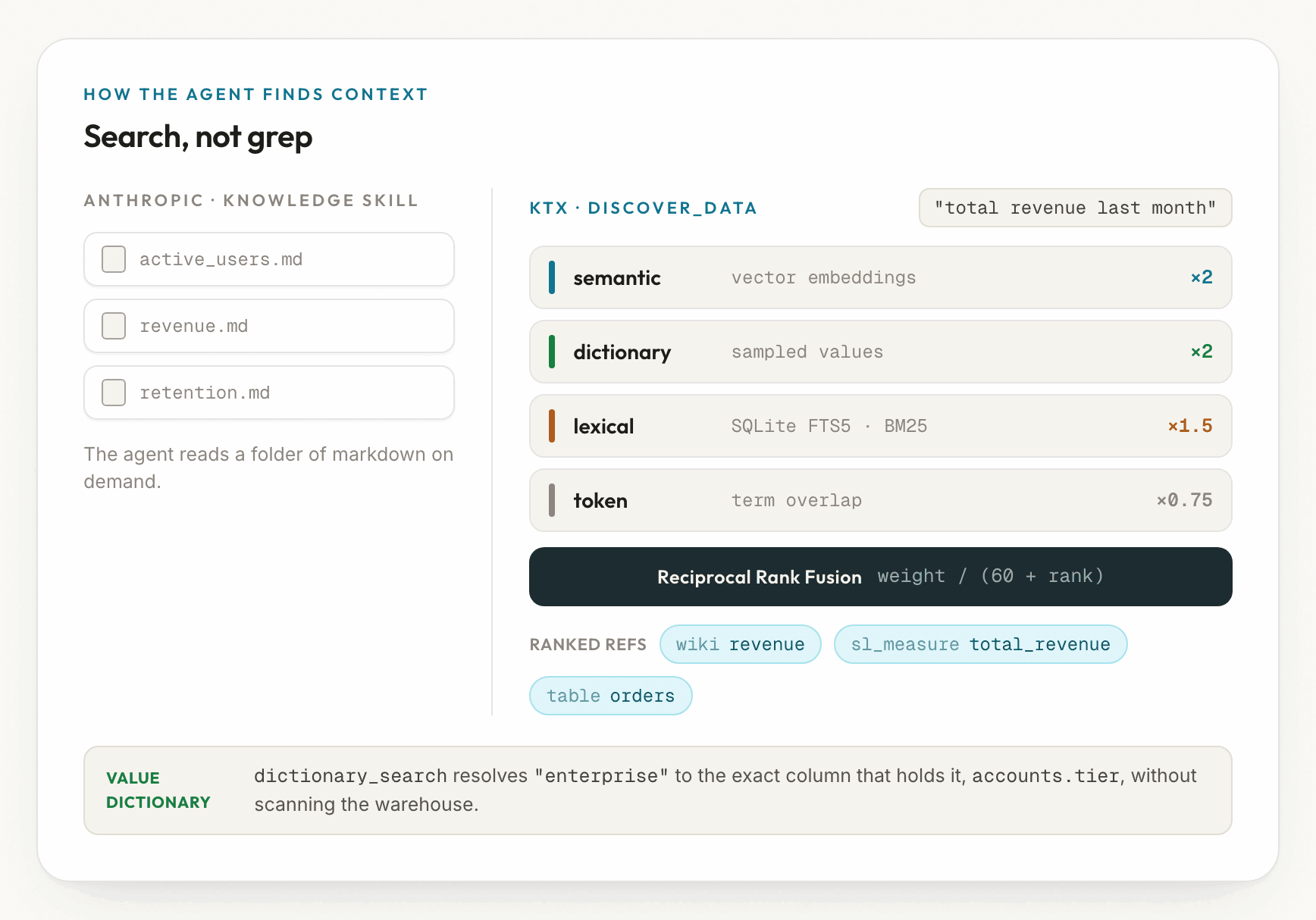
discover_data runs four search lanes in parallel, weights them, and fuses the results with Reciprocal Rank Fusion:
- semantic, vector embeddings
- dictionary, sampled warehouse values
- lexical, full-text BM25
- token, a short-query fallback
It searches everything at once (wiki pages, metrics, dimensions, tables, and columns) and returns one ranked list.
The most useful piece for accuracy is the value dictionary. Ask "how many enterprise accounts" and the agent does not have to guess which column holds "enterprise": dictionary_search resolves the value to the exact column without scanning the warehouse. That is something a folder of markdown cannot do, and it attacks Anthropic's concept-to-entity ambiguity head on.
This is the same lesson Anthropic landed on, applied at retrieval time: curate the layer, then make it findable. ktx agrees that raw history is not the answer. The wiki and semantic layer are the distilled reference docs. ktx just serves them through a ranked index instead of file reads.
Sources of truth a human owns
The context ktx builds is two committed surfaces, by design. One is executable, one is prose.
A semantic source (semantic-layer/warehouse/orders.yaml) holds approved metrics, grain, and the join graph, instead of free-form SQL:
name: orders
table: public.orders
descriptions:
user: Orders placed through the storefront.
grain:
- id
columns:
- name: id
type: number
- name: status
type: string
- name: amount
type: number
measures:
- name: order_count
expr: count(*)
- name: total_revenue
expr: sum(amount)
joins: []And business context as a searchable wiki note (wiki/global/revenue.md), the thing that resolves "which revenue?":
---
summary: Paid order value after refunds
tags: [finance, orders]
sl_refs: [warehouse.orders]
usage_mode: auto
---
Revenue is paid order amount after refund adjustments.
Use `orders.total_revenue` for recognized order value and
`orders.order_count` for paid order volume.The two surfaces link to each other, and ktx keeps the links valid, so a stale note can never quietly point the agent at a definition that no longer exists. Anthropic warns that governance "without enforcement quickly decays back to the multiple candidates problem." This is that enforcement, for prose.
Watching the agent work
Now ask your agent a normal question: "What was total revenue last month?", and instead of re-exploring your schema and hand-writing SQL, it follows the ktx-analytics skill and uses ktx's tools:
discover_datasearches the wiki and semantic layer and surfaces theorders.total_revenuemeasure plus therevenue.mdnote explaining it is paid order value after refunds. This kills retrieval failure and starts on concept-to-entity ambiguity.sl_queryrequests thetotal_revenuemeasure by month. ktx's deterministic compiler plans the join graph and generates canonical, read-only SQL, so the agent never hand-writes the metric. This kills ambiguity for good. (For the rare question the semantic layer does not cover, the agent drops tosql_execution, which runs one parser-validated read-only query.)- The agent returns a number that matches your approved definition, with the SQL and sources attached.
And when an agent learns something new, like "ARR is stored in cents in this warehouse", it calls memory_ingest to write that rule back into the wiki, so the next question starts with better context.
That deterministic compiler is the piece that turns a declarative request into a correct number, and it is a whole topic of its own. We wrote about how it plans join paths and avoids the fan-out that silently inflates a measure in Why your data agent double-counts revenue. The short version: the agent sends measures and dimensions, never a JOIN or a GROUP BY, and the compiler owns the SQL.
How ktx keeps itself current: the ingest is a pull request
Anthropic's stack assumes mature data foundations and a team that maintains them. ktx has to build and maintain that layer for you, continuously, as schemas drift. The mechanism is the most software-like part of the whole system: every ingest is a pull request against your context repo.
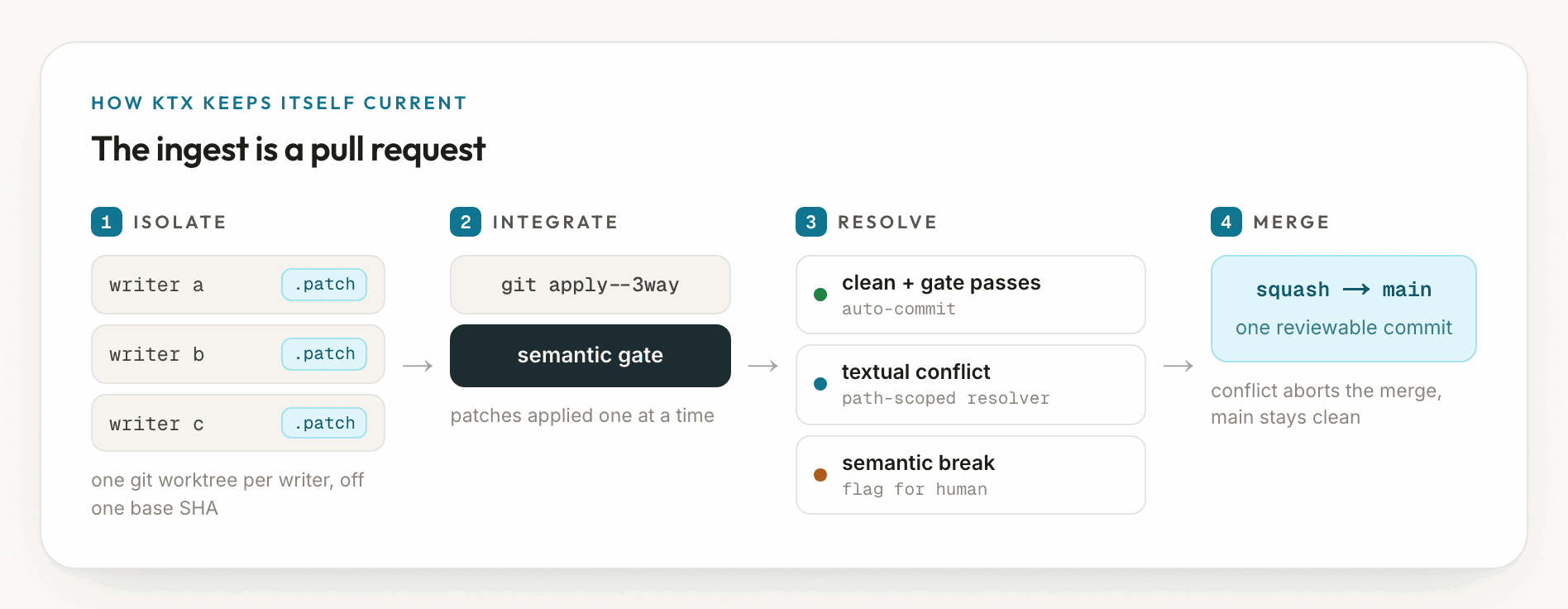
Here is what that means concretely:
- Isolate. Each writer works in its own git worktree, so several can build context in parallel without clobbering each other.
- Integrate. Their changes are applied one at a time behind a semantic gate. Clean changes that pass commit on their own.
- Resolve. A textual conflict goes to a narrow auto-resolver. A semantic break, like a metric that now contradicts an existing one, is always flagged for a human.
- Merge. The whole job lands as one reviewable commit. If it would conflict, the merge aborts and
mainstays clean.
This is where ktx lands closest to Anthropic, not furthest. Anthropic says to treat data assets with the rigor of software, version control, CI, the change in the pull request. ktx makes that literal: your context is a git repo, and every ingest is one reviewable diff. Mechanical changes merge on their own, anything definitional is flagged for a human, so a person still owns every contested definition.
How to set this up at your company
ktx is a CLI that builds and maintains this exact repository for you. Install it and run the setup wizard:
npm install -g @kaelio/ktx
ktx setupThe wizard walks through 7 steps:
- Init project: scaffolds a git repo (
ktx.yaml,semantic-layer/,wiki/,raw-sources/,.ktx/). - LLM backend: the local Claude Code session by default (no API key needed), or an Anthropic API key, Google Vertex, or your local Codex session.
- Embeddings: OpenAI (
text-embedding-3-small) or localsentence-transformers, for semantic search across your context. - Connect your warehouse, read-only: Postgres, Snowflake, BigQuery, ClickHouse, MySQL, SQL Server, or SQLite. ktx never writes to your database.
- Context sources: point ktx at the knowledge you already have, like your dbt repo, MetricFlow, Metabase, LookML, Looker, or Notion. It ingests them instead of asking you to re-document everything.
- Build context:
ktx ingestscans your schema, samples tables, infers typed relationships with confidence scoring, embeds your definitions, and reconciles everything into reviewable files (both a semantic layer and a business context layer). - Wire up your agent: installs the MCP server and the
ktx-analyticsskill into Claude Code, Claude Desktop, Codex, Cursor, or OpenCode.
When it's done you have a real, version-controlled repo, and unlike a hand-built stack, ktx keeps it updated continuously on every ktx ingest.
What's coming next
The validation layer. ktx harvests corrections and gates definitions on a compile check, but answer-correctness evals and online adversarial review are not built yet. Adversarial review is a natural next addition, and it is exactly the kind of thing that is easy to contribute to an open-source project.
Governance. Anthropic is candid that this one is hard: "governance without enforcement otherwise quickly decays back to the multiple candidates problem." Once you need to control which stakeholders see which context, tables, or rows, a shared repository is not enough on its own. ktx is read-only and fully local today, which contains the blast radius, and fine-grained, role-aware access control is on the roadmap.
Try it out
Anthropic showed the industry that the bottleneck for agentic analytics is not the model, it is the context around it. We think that context layer should not be something only teams like Anthropic can build. So we open-sourced ours: github.com/Kaelio/ktx.
npm install -g @kaelio/ktx && ktx setupIt runs locally, it is read-only, and the only data that leaves your machine is what you send to the LLM provider you configured.
FAQ
What is ktx?
ktx is an open-source, installable context engine for data agents. It packages the same four layers as Anthropic's internal agentic analytics stack (data foundations, sources of truth, skills, and validation) into one CLI that scans your warehouse, drafts a semantic layer and a business-context wiki, serves them to your agent over MCP, and ships an analytics skill that teaches the agent how to use them. It's Apache-2.0 and read-only by design: github.com/Kaelio/ktx.
What are the four layers of Anthropic's agentic analytics stack?
Data foundations (the warehouse models and their metadata), sources of truth (a semantic layer plus business context the agent navigates), skills (the markdown the agent reads to route and to run the query process), and validation (offline evals, ablation, and online adversarial review). Anthropic credits the skills layer with the jump from 21% to 95%+ accuracy.
Why do data agents return wrong analytics answers?
Anthropic names three causes: concept-to-entity ambiguity (the agent picks the wrong fields), staleness (definitions and schemas drift out from under the agent), and retrieval failure (the right context exists but the agent doesn't find it). Because data is not software, no compiler catches a wrong number, so every layer of the stack exists to kill one of these three.
How is ktx different from Anthropic's internal setup?
ktx ships the same kind of analytics skill Anthropic describes, so the layers line up closely. The two differences are mechanism and maturity. For retrieval, Anthropic has the agent read a folder of markdown on demand, while ktx serves a curated wiki and semantic layer through a four-lane hybrid search and a value dictionary. And Anthropic's hardest accuracy gains came from validation (evals and online adversarial review), which is the layer ktx is thinnest on today and where it's still building.
How do I install ktx?
Run npm install -g @kaelio/ktx then ktx setup, and the wizard walks through connecting your warehouse read-only, pointing at your existing context sources, building the context, and wiring up your agent. ktx is Apache-2.0 and read-only by design.